[DB] 데이터베이스 정규화 / 반정규화의 개념
1. 정규화(Normalization) 란?
정규화(Normaliztion): 이상 현상이 있는 테이블을 분해하여 이상 현상을 없애는 방법
테이블을 분해하는 정규형 단계가 높아질수록 이상 현상이 줄어든다.
정규화의 목적
- 데이터의 중복을 줄여 저장공간을 최소화 하고, 데이터 무결성을 유지
- 데이터의 변경이 있을 때 이상 현상을 줄일 수 있다.
- 테이블을 논리적, 직관적으로 구성할 수 있다.
정규화의 장점
- 데이터베이스 변경 시 이상 현상을 제거할 수 있다(올바른 데이터를 얻는다).
- 정규화된 데이터베이스 구조에서는 새로운 데이터 형을 확장 하려고 할때, 테이블 구조를 변경하지 않거나 일부만 변경해도 된다.
정규화의 단점
- 테이블을 분해하는 과정에서 테이블 간의 JOIN 연산이 많아진다.
- 지나치게 많은 JOIN 연산 때문에 생긴 성능 저하를 반정규화를 적용하여 개선할 수 있다.
2. 정규화의 단계
[ 제1 정규화(1NF) ]
제1 정규화란 테이블 컬럼이 원자값( 하나의 값 )을 갖도록 테이블을 분해하는 것이다.
- 제1 정규화 규칙 -
1. 각 컬럼은 하나의 값(속성)만을 가져야 한다.
2. 각 컬럼은 같은 종류나 타입의 값을 가져야 한다. (ex. 문자열과 숫자를 동일한 컬럼에 저장 x)
3. 컬럼의 배치 순서는 상관이 없어야 한다.
[ 제1 정규화 예시]
예시를 보면 특정 학생의 과목이 두개의 값으로 1번 규칙을 위반하고 있다.

아래와 같이 분해 하여 제1 정규화를 만족할 수 있다.

[ 제2 정규화(2NF) ]
제2 정규화란 제1 정규화를 지키고있는 테이블에 대한 부분 함수 종속성을 제거하는 과정이다.
모든 기본키의 부분 집합에 의존하는 컬럼들을 분리하여 새로운 테이블을 만드는 것이다.
쉽게 설명해서, 현재 테이블의 주제와 관련없는 컬럼을 다른 테이블로 빼는 작업이다.
- 제2 정규화 규칙 -
1. 제1 정규화를 만족해야한다.
2. 모든 컬럼이 완전 함수 종속을 만족해야한다.
[ 제2 정규화 예시]
예시를 보면 특정 학생의 성적을 알기 위해서 학생번호 + 과목을 알아야한다.(ex. A104 학생의 C# 성적은 80점)
그러나 특정 과목의 강사를 알고싶다면 과목명만 알아도 어느 강사인지 알수 있다.(ex. C# 강사 박임재)
아래의 테이블에서 기본키(학생 번호, 과목)는 복합키이다.
그러나 강사 컬럼은 (학생 번호, 과목)에 종속되지 않고 (과목)에만 종속되는 부분적 종속이다.
따라서 제2 정규화를 만족하지않는다.
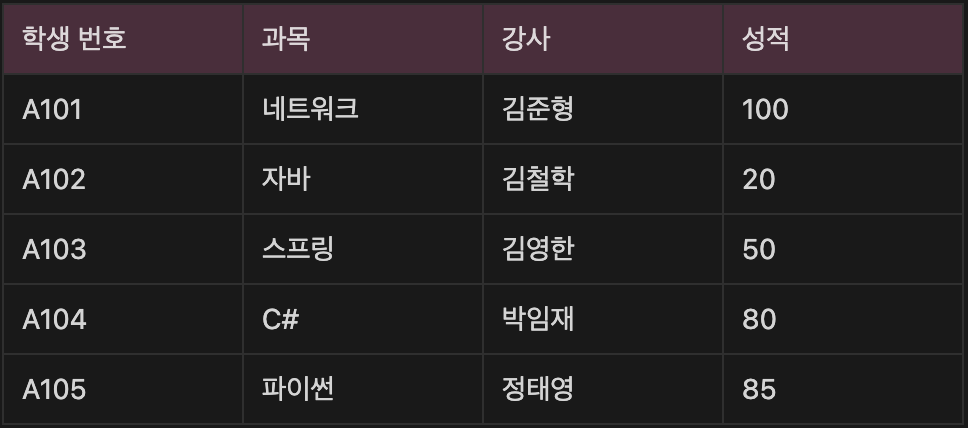
제2 정규화에 맞게 아래와 같이 테이블을 분해 해야한다.

[ 제3 정규화(3NF) ]
제3 정규화란 제2 정규화를 지키고있는 테이블에 대한 이행적 종속을 없애도록 테이블을 분해하는 것이다.
이행적 종속이란 A → B, B → C가 성립할 때 A → C가 성립되는 것을 의미한다.
- 제3 정규화 규칙 -
1. 제2 정규화를 만족해야한다.
2. 기본키를 제외한 속성들 간의 이행 종속성이 없어야 한다.
[ 제3 정규화 예시]
아래의 테이블을 보면 ID를 알면 등급을 알 수 있다.
등급을 알면 할인율을 알 수 있다. 따라서 ID를 알면 할인율을 알 수 있다.
그래서 이행적 종속이 존재하므로 제3 정규형이 적합하지않다.

제3 정규화에 맞게 아래와 같이 테이블을 분해 해야한다.

[ BCNF(Boyce-codd Normal Form) ]
BCNF는 3차 정규화에서 해결할 수 없는 이상현상을 해결 하기위해 3차 정규화를 강화한 버전이다.
3차 정규화를 만족하면서 모든 결정자가 후보키 집합에 속한 정규형이다.
모든 결정자가 후보키 집합에 속해야 한다는 뜻은 후보키 집합에 없는 컬럼이 결정자가 되어서는 안 된다는 뜻이다.
- BCNF 규칙 -
1. 제3 정규화를 만족해야한다.
2. 모든 결정자가 후보키 집합에 속해야 한다.
아래 테이블을 보면 기본키(학생 번호, 과목)로 강사를 알 수 있다.
그러나 같은 과목을 다른 강사가 가르칠 수도 있어서 과목 → 강사 의 종속 관계는 성립하지 않는다.
그러나 특정 강사가 어떤 과목을 가르치는지는 알 수 있으므로 강사 → 과목 종속 관계는 성립한다.
[ BCNF 예시]

BCNF에 맞게 아래와 같이 테이블을 분해 해야한다.

3. 반정규화란?
- 데이터베이스 성능 향상을 위해서 데이터 중복을 허용하고 조인을 줄이는 방법이다.
- 반정규화는 조회 속도를 향상시키지만 데이터 모델의 유연성은 낮아진다.
- 반정규화는 데이터를 조회할 때 조인으로 인한 성능저하가 예상될 때 사용한다.
반정규화 절차
- 반정규화 대상 조사 및 검토(데이터 처리 범위, 통계성 등을 확인하여 대상 조사)
- 다른 방법유도 검토(반정규화를 수행 전 다른 방법이 있는지 검토)
- 반정규화 적용(테이블, 속성, 관계 등을 반정규화 한다)
반정규화 기법
[ 테이블 반정규화 ]
계산된 컬럼 추가
- 프로그램을 통해서 총 주문금액, 평균주문 금액 등을 미리 계산하고 결과를 특정 컬럼에 추가
테이블 수직 분할
- 하나의 테이블을 두개 이상의 테이블로 분할. 즉 칼럼을 분해하여 새로운 테이블을 만드는것
테이블 수평 분할
- 하나의 테이블에 있는 값을 기준으로 테이블을 분해하는 방법
[Partition]
- 데이터베이스에서 파티션을 사용하여 테이블을 분할할 수 있다
- 파티션을 사용하면 논리적으로는 하나의 테이블이지만, 여러 개의 데이터 파일에 분산되어 저장된다.
- Range Partition: 데이터 값의 범위를 기준으로 파티션을 수행한다.
- List Partition: 특정한 값을 지정하여 파티션을 수행한다.
- Hash Partition: 해시 함수를 적용하여 파티션을 수행한다.
- Composite Partition: 범위와 해시를 복합적으로 사용하여 파티션을 수행한다.
[파티션 테이블의 장점]
- 데이터 조회 시에 엑세스(Access) 범위가 줄어들기 때문에 성능이 향상된다.
- 데이터가 분할되어 있기 때문에 I/O의 성능이 향상된다.
- 각 파티션을 독립적으로 백업 및 복구 할 수 있다.
테이블 병합
- 1:1 관계의 테이블을 하나의 테이블로 병합하여 성능향상
- 1:N 관계의 테이블을 병합하여 성능을 향상( 데이터 중복이 발생하는 단점이 있다)
- 슈터 타입과 서브 타입 관계가 발생하면 테이블을 통합하여 성능향상
[Super Type과 Sub Type]
- 슈퍼타입과 서브타입의 관계는 배타적 관계와 포괄적 관계가 있는데,
배타적 관계는 고객이 개인 고객이거나 법인 고객인 경우를 의미한다.
- 포괄적 관계는 고객이 개인고객일 수도 있고 법인고객일 수도 있는 것이다.
